Our perception of data can influence our perception of an issue. Current budget debates in Congress offer an example of data visualization’s power over how we understand complex policy debates, such as how to address the looming funding shortfall for the Social Security Disability Insurance (DI) program.
More than 12 million Americans received benefits from the DI program in 2015. An underlying structural problem (DI pays out more benefits than it collects in revenues) places the program under considerable fiscal strain. The program continues to pay full benefits because it can draw on support from the DI trust fund, an accounting mechanism that records the balance between money coming in and money going out.
When that fund is exhausted, benefits will be reduced, or Congress will have to shift funds from another source, such as the Old-Age and Survivors Insurance trust fund. In either case, DI’s long-term financial stability is in jeopardy, and policymakers need to act soon to avert these scenarios.
Maps showing the geographic dispersion in the DI recipiency rate—the number of people receiving DI benefits as a share of the population ages 18 to 65—often pops up in articles and research examining the issue. But how the states are placed into groups (or “bins”) and the resulting map shading—and, ultimately, our perception of the data—will depend on choices the map creator makes.
Pros and cons of four primary binning methods
There are four primary binning methods for creating a map.
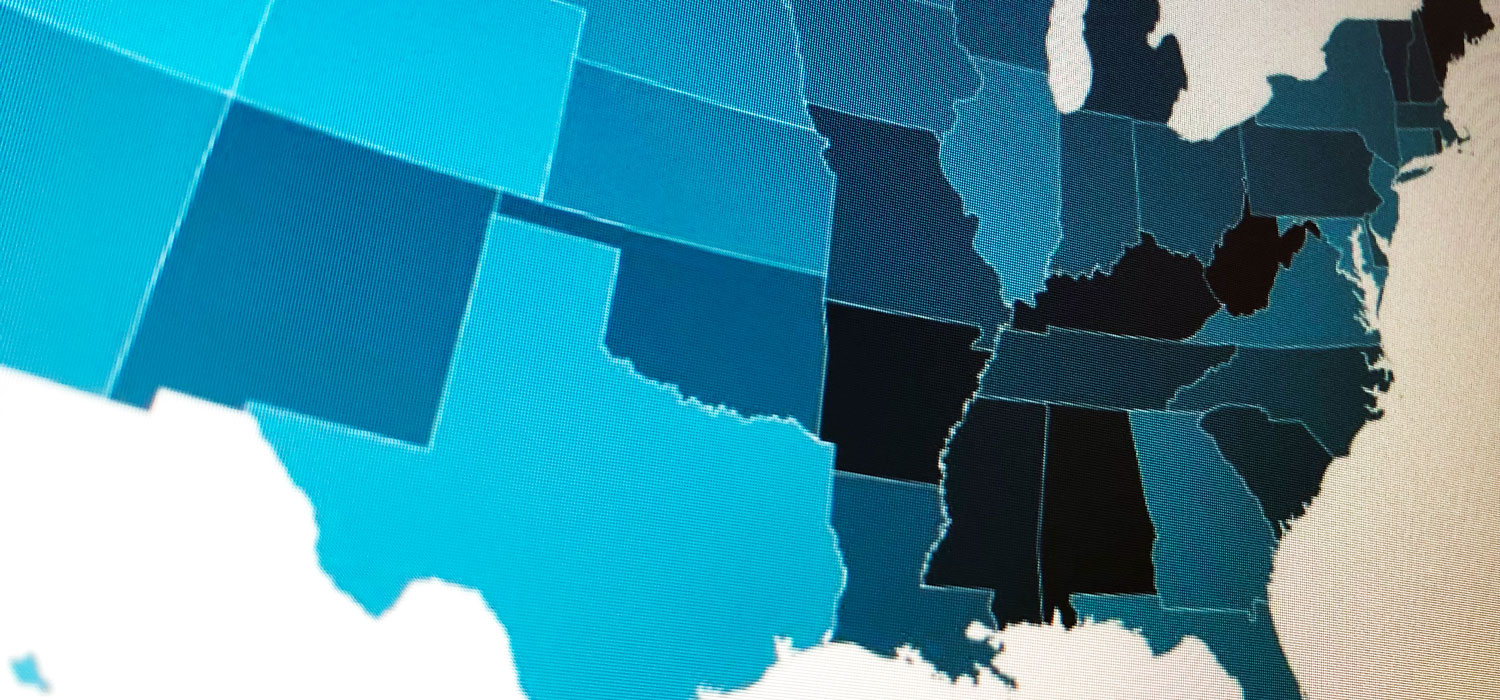
No bins. This is essentially a continuous color ramp in which each data value receives its own gray tone. On one hand, this is an easy approach because the map creator doesn’t have to think too much. The colors ramp up from a light color for the lowest value to a dark color for the highest value. On the other hand, the resulting color gradient may generate spatial patterns masked by subtle changes in color. In this example, it’s hard to distinguish the differences between Indiana, Michigan, and Ohio.
 Equal interval bins. In maps with a discrete number of bins, the default approach typically divides the data range into n bins and places the geographic observations into those bins. For example, in a map with four bins and a data range from 1 to 100, we end up with four equal groups (1–25, 26–50, 51–75, and 76–100). (This is essentially the special, discrete case of the no bins category.)
Equal interval bins. In maps with a discrete number of bins, the default approach typically divides the data range into n bins and places the geographic observations into those bins. For example, in a map with four bins and a data range from 1 to 100, we end up with four equal groups (1–25, 26–50, 51–75, and 76–100). (This is essentially the special, discrete case of the no bins category.)
This approach can more clearly distinguish geographic units (such as states), but it can mask the magnitudes of those changes by putting states in the same or different bins. In cases where the distributions are highly skewed, this approach may end up with an uneven distribution of geographic units across the bins. In the map below, there are 17 states (plus Washington, DC) in the first category, 13 in the second, 13 in the third, 2 in the fourth, and 5 in the fifth.

Data distribution bins. We could also cut the data into different bins. Instead of having n equal bins regardless of how many observations go in each (i.e., the equal interval binning method), we can have n bins that have the same number of observations in each, such as quartiles (4 groups), quintiles (5), or deciles (10). Map creators could use other statistical measures to collapse the data, such as the variance or standard deviation.
This approach clearly shows differences between the geographic units, but the created cutoffs may not be numerically meaningful. In this map, Michigan is in the top group with a recipiency rate of 6.52 percent, and Vermont is grouped in the next bin with a similar participation rate of 6.43 percent.

Arbitrary bins. In this approach, the map creator chooses the bin cutoffs based on round numbers, natural breaks, or arbitrary selection. This method enables the creator to avoid some of the odd breaks that might occur, such as the Michigan-Vermont example above, but it also might present a biased or misleading picture by simply selecting round or arbitrary groups. A method in which the selected bins are based on round numbers—even without looking at the data—might look like this.

Alternative options
This isn’t to say any of these maps are right or wrong, but they highlight the importance of binning decisions when making a choropleth map. To make the best binning decision, we can draw on Mark Monmonier’s book, How to Lie with Maps. Instead of using equally sized bins arbitrarily or letting the software tool decide which breaks to use, look at—and show—the actual distribution. If I add a column chart to the arbitrary bin method map, the bin breaks and the distinct differences between the values become clear.

Another alternative is to include the number of observations in each bin. The Urban Institute’s State Economic Monitor includes interactive maps and column charts so that the user gets both views. A bar chart in the legend could also denote the number of observations in each bin (this screenshot has the original map with an additional bar chart next to the legend).

Although these approaches take up more room, they give readers a clearer picture of the data. As creators of visual content bringing the best data and evidence to bear on important policy issues, we must think carefully, strategically, and purposefully about how we present our analysis and not let the tools think for us.
Let’s help communities build more secure, hopeful futures.
Today’s complex challenges demand smarter solutions. Urban brings decades of expertise to understanding the forces shaping people’s lives and the systems that support them. With rigorous analysis and hands-on guidance, we help leaders across the country design, test, and scale solutions that build pathways for greater opportunity.
Your support makes this possible.